

Hoy en día, quienes buscan un agente de IA capaz de buscar vuelos, completar formularios o explorar listas de productos de forma autónoma en el navegador siguen dependiendo de sistemas cerrados. Los agentes web más avanzados pertenecen a empresas que no revelan ni sus datos de entrenamiento ni sus métodos.
El Allen Institute for AI (AI2) quiere cambiar esta situación con MolmoWeb, un agente web completamente abierto disponible en dos versiones con 4.000 y 8.000 millones de parámetros, junto con todos los datos de entrenamiento, pesos del modelo y herramientas de evaluación.
“Los agentes web hoy están donde estaban los grandes modelos de lenguaje antes de OLMo”, escribió el equipo en su anuncio. Según los investigadores, la comunidad de código abierto necesita una base abierta.
MolmoWeb busca ofrecer precisamente eso sin destilar conocimientos de sistemas propietarios. En su lugar, el entrenamiento se basa en una mezcla de demostraciones humanas y trayectorias de navegación generadas automáticamente. Los modelos se entrenaron exclusivamente mediante ajuste fino supervisado en 64 GPUs H100, sin aprendizaje por refuerzo. La base es la arquitectura Molmo2, con Qwen3 como modelo de lenguaje y SigLIP2 como codificador de visión.
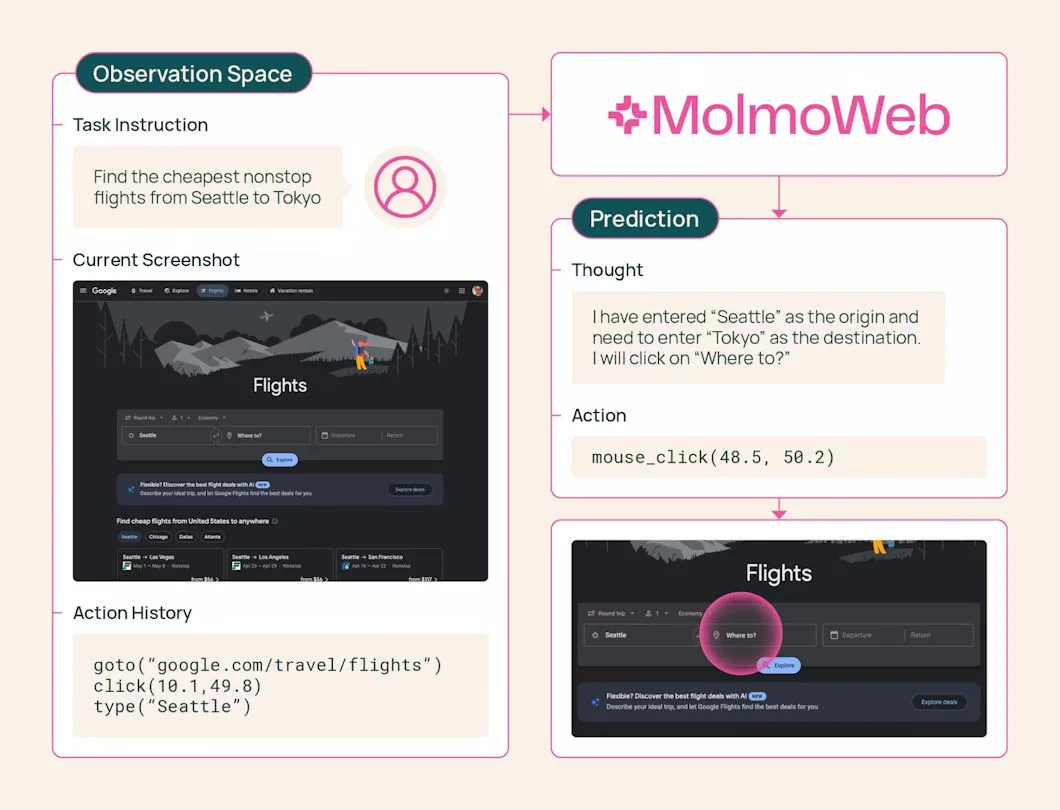
El agente ve lo que ve el usuario
El agente recibe una captura de pantalla de la vista actual del navegador, formula una breve idea sobre qué hacer a continuación y ejecuta una acción: hacer clic, escribir, desplazarse, cambiar pestañas o abrir una URL. Después toma una nueva captura y repite el proceso.
MolmoWeb no lee el código fuente del sitio ni accede a la estructura técnica de la página. Funciona exclusivamente con lo que un usuario vería en la pantalla. Según los desarrolladores, esto hace que el agente sea más robusto, ya que la apariencia de un sitio cambia con menos frecuencia que su código subyacente. Además, facilita comprender por qué el agente toma determinadas decisiones.
El mayor conjunto de datos público de su tipo
La verdadera innovación podría no ser el modelo en sí, sino el conjunto de datos de entrenamiento llamado MolmoWebMix. Hasta ahora, el mayor obstáculo para crear agentes web abiertos ha sido la falta de datos adecuados.
MolmoWebMix consta de tres componentes. Primero, los investigadores pidieron a trabajadores que realizaran tareas reales de navegación y registraron cada clic y cambio de página. Esto generó 36.000 trayectorias completas en más de 1.100 sitios web. El equipo lo describe como el mayor conjunto de datos público de ejecución de tareas web humanas hasta la fecha.
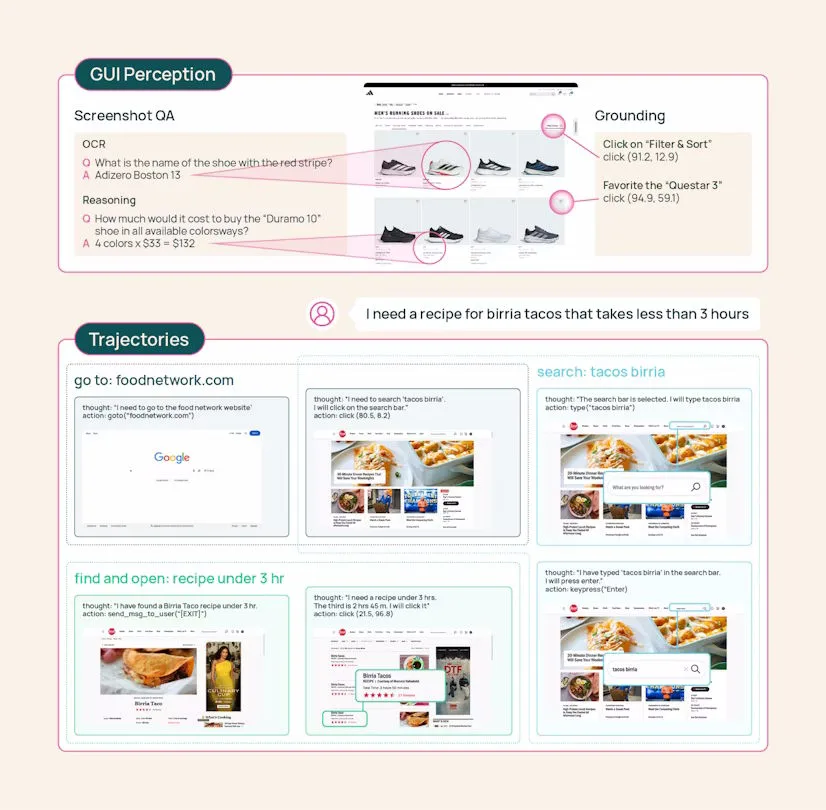
En segundo lugar, agentes automatizados generaron trayectorias adicionales para ampliar el conjunto de datos. Se utilizó un sistema de tres roles: un planificador basado en Gemini 2.5 Flash divide las tareas en subobjetivos, un operador ejecuta las acciones del navegador y un verificador basado en GPT-4o confirma mediante capturas si se alcanzaron los objetivos.
Finalmente, el conjunto incluye más de 2,2 millones de pares de preguntas y respuestas basadas en capturas de pantalla. La localización de elementos de interfaz se entrena con un dataset independiente con más de siete millones de ejemplos.
Un resultado llamativo del artículo es que MolmoWeb aprende mejor de trayectorias sintéticas que de demostraciones humanas. Los investigadores explican que los humanos tienden a explorar más y tomar rutas menos directas.
Los agentes automatizados, en cambio, encuentran rutas más directas, lo que facilita el aprendizaje por imitación. Además, los experimentos muestran que solo el 10% del dataset ya ofrece entre el 85% y el 90% del rendimiento final.
Modelos pequeños superan a otros más grandes
A pesar de su tamaño, ambos modelos MolmoWeb logran resultados de vanguardia entre los agentes web abiertos. En el benchmark WebVoyager, el modelo de 8B alcanza el 78,2%.
Esto supera al modelo abierto Fara-7B y se acerca al o3 de OpenAI con 79,3%. En DeepShop, MolmoWeb-8B queda solo seis puntos por detrás de GPT-5.
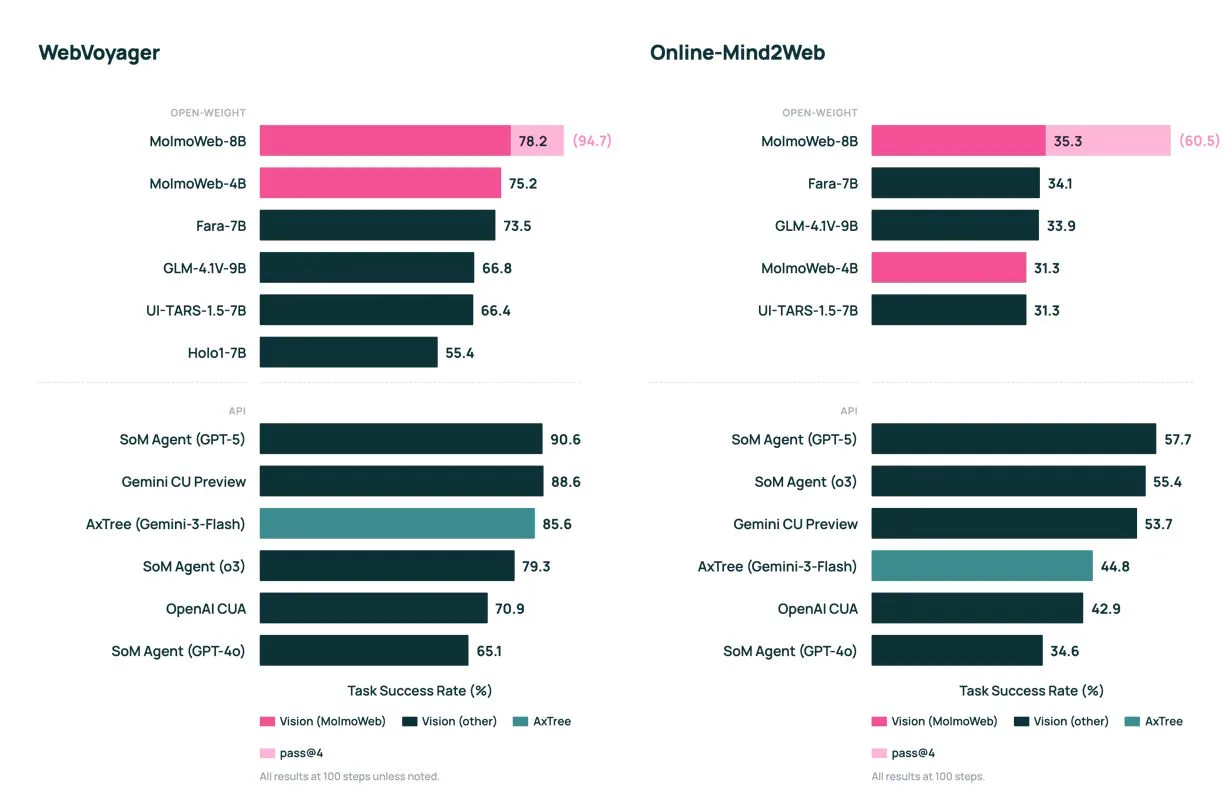
Sin embargo, MolmoWeb aún queda cinco puntos por detrás de su "profesor", un agente basado en Gemini con acceso a la estructura técnica del sitio. Esto refleja el coste del enfoque puramente visual.
Otro hallazgo es que repetir las tareas varias veces aumenta la tasa de éxito del 78,2% al 94,7%, lo que demuestra que mayor capacidad de cómputo mejora la fiabilidad.
Sin login, sin pagos, muchas preguntas abiertas
Los desarrolladores reconocen las limitaciones del sistema. MolmoWeb puede leer incorrectamente texto en capturas, y el rendimiento disminuye con instrucciones complejas. Las tareas con inicio de sesión o pagos no se entrenaron por razones de seguridad.
En la demo online, solo se permiten ciertos sitios y se bloquean campos sensibles. Estas medidas, sin embargo, no forman parte del modelo en sí.
MolmoWeb está disponible en Hugging Face y GitHub bajo licencia Apache 2.0.
MolmoWeb amplía la tendencia hacia agentes abiertos iniciada por proyectos como OpenSeeker y refuerza el desarrollo de automatización de navegador basada en IA.
El Allen Institute for AI también ha sufrido recientemente la salida de varios investigadores clave, contratados por Microsoft para su nuevo equipo de superinteligencia liderado por Mustafa Suleyman.

 ES
ES  EN
EN